
让不懂建站的用户快速建站,让会建站的提高建站效率!

快乐彩正版app下载官网
你的位置:快乐彩正版app下载官网 > 单双 > 快乐彩app官方最新版下载 10万引普林斯顿刘壮最新访谈: 架构没那么重要, 数据才是王谈
发布日期:2026-05-01 01:00 点击次数:196

援用量突出10万次,清华姚班学友,ConvNeXt、ImageBind、《无归一化的Transformer》……这些论文的作家——
普林斯顿大学助理教悔刘壮,在学术圈是一个颇为特别的存在——他的每一篇论文险些都在质疑某个“理所自然”的假定。
架构的确重要吗?数据集的确满盈各样吗?归一化层是必需的吗?大言语模子有全国模子吗?AI智能体能替代博士生吗?

在《信息瓶颈》的最新播客中,刘壮和主捏东谈主RavidShwartz-Ziv、AllenRoush张开了长达一个多小时的对谈,解答了这些问题。
刘壮给出了几个中枢判断(太长不看版)
1、架构选什么,没你想的重要
只须把残差勾通、显示观点、归一化层、线性层这四大基础作念对,不管用ConvNet如故Transformer,最终都会落在归拢条性能弧线上。
以前十年真实鞭策AI逾越的,是更猛进程上是数据限度和算计限度,而不仅仅架构蜕变。
2、数据集远莫得咱们以为的各样
他和何恺明作念了一个实验:磨真金不怕火神经聚积来判断一张图片来自哪个数据集。
终局在三个堪称“各样化”的亿级数据集上,准确率高达80%以上——
证据这些数据集在模子眼里仍然曲直分明,距离“无偏的全球分散”还差得远。
3、大言语模子有全国模子,但只在言语空间里
LLM在高级次事件推理上施展出色,但视觉空间的清雅全国模子咱们还莫得——
根蒂原因是视觉数据的信息密度太高,现存算力还处理不了
何况对于突出一半的责任场景(尤其是数字化的白领责任),根蒂不需要视觉全国模子。
4、顾忌才是现时最大的瓶颈,不是手艺
现存模子的推理手艺照旧满盈强,真实缺的是领会的经久顾忌。
咱们需要那么多智能体配合,恰正是因为一个智能体记不住悉数事情。

5、自主科研还没到位,AI替代不了斟酌生
他亲自测试过让ClaudeCode在一两天内孤苦完成一个斟酌技俩。
论断是:低档次任务还行,但刻薄故瞻仰的问题、遐想实验、保捏标的感——这些还作念不到。
通盘访谈有一条荫藏的干线:咱们在AI规模里奉为圭臬的好多东西,其实是历史偶然。
而真实决定成败的,往往是那些更朴素、更枯燥的成分——数据、限度、顾忌
以下是量子位梳理的刘壮最新访谈,为便于贯通,有部分删减和润色,并在必要的处所添加了编者注,诸君enjoy~
架构没那么重要,但细节决定一切
Ravid:今天咱们会聊聊你的一些论文。总体上,咱们要辩论现在AI中真实重要的构成部分是什么。你的斟酌效力好多,我想咱们可以从“哪些组件最枢纽”运行。
几年前,你发表了一篇对于“面向2020年代的卷积神经聚积”的论文。你能先先容一下这篇论文,然后咱们再来拆解现时AI系统的各个构成部分吗?
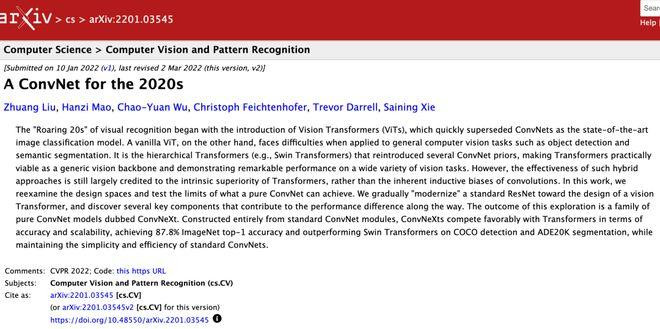
刘壮:嗯,自然。那是一段相当道理的履历。
这篇论文咱们是在2021年写的,那时候Transformer刚刚通过视觉Transformer的引入进入了算计机视觉规模,通盘视觉社区都在从传统的卷积存集切换到视觉Transformer,性能也越来越好。
在这项责任中,咱们想斟酌:ConvNet是否的确照旧丧失了竞争力?
是否有可能通过系统性地律例悉数遐想细节,来考证ConvNet能否被当代化、达到其时视觉Transformer的水平?
咱们想搞了了,Transformer和ConvNet之间看似存在的性能差距,究竟是源于架构实质的不同——比如用显示观点如故卷积——如故源于一些看似微弱的遐想细节。
最终咱们发现谜底是后者。
经过无数对ConvNet各组件的斟酌,咱们最终让模子在多种任务上达到了其时最强视觉Transformer的水平。
这证据,不管选拔ConvNet如故视觉Transformer,只须把悉数细节都作念对,就能在视觉任务上达到同等的前沿性能。
Ravid:你现在还服气这小数吗?你还认为架构其实并不重要吗
刘壮:我不会这样说——总体上我倾向于认可,但我不会说架构不重要
我的瞻仰是,只须你把悉数细节都作念对,只须你对遐想空间探索得满盈充分,就会拘谨到一个类似“帕累托前沿”的点——在精度和效力之间赢得最好均衡。
要冲破这条前沿线是曲常贫窭的。
我以为以前这样多年,除了几年前照旧老练的那些架构除外,真实被豪放采用的架构蜕变其实并未几。
不外这个探索经过自己相当道理。
最近,一些开源模子公司,比如Kimi、DeepSeek,还在继续折腾架构,比如若何改残差勾通、若何勾通不同层,我相当尊重这类责任。
事实上,学术界现在架构斟酌没那么活跃,部分原因是咱们背负不升引满盈劝服力的限度来考证这些效果所需的算计资源。
但我我方如故会用学校的资源去尝试。现在有了ClaudeCode的匡助,我可以我方起原写代码去探索,这相当道理。
从实用角度来看,我认为咱们用什么数据磨真金不怕火模子,比选拔什么架构更重要——前提是输入输出接口不变。
架构实质上是咱们参数化函数近似器的样子,这是神经聚积或深度学习最基本的功能。
只须你把几件事作念对,比如用残差勾通、用显示观点或其他合理的机制、在安妥的位置放激活函数和前馈层,你就能相当接近以致达到性能与效力的前沿弧线。
从实践诳骗的角度,我认为更重要的是:这个模子用什么数据磨真金不怕火的?它若何处理凹凸文和顾忌?
在凹凸文和顾忌这方面,如实有一些架构责任在管理这个问题。
我以为这才是让AI再上一个台阶最攻击需要管理的问题。
Allen:笔据我的贯通,你们是把ResNet冉冉往类似SwinTransformer的遐想标的当代化,最终得到一个能与Transformer强力竞争的ConvNet。
在那篇论文里,哪一个消融实验最让你对“Transformer的上风究竟从何而来”改变了看法?
刘壮:哪一个?我以为是每一个。
你看那张图,莫得任何单一转变能大幅拉升性能。有些转变比其他的更灵验,但莫得哪一个能改变一切。
ConvNeXt论文的Figure2,展示了ResNet当代化的完整经过和每一步对应的性能变化
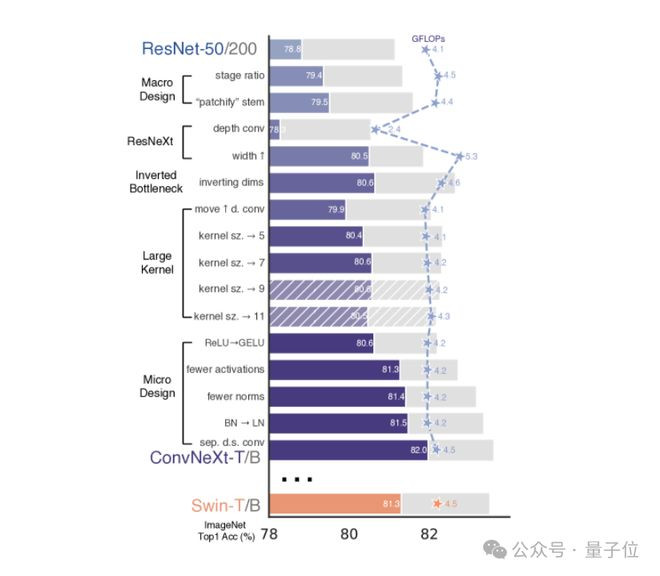
也许激活函数的使用,以及减少归一化层的数目,是让我比拟感兴致、也有昭着性能升迁的一个点。
但真实起作用的是把悉数转变类似在沿途
这些看似微弱的组件,当咱们把它们组合起来的时候,产生的性能差距,是那种泛泛只须把卷积换成显示观点这种大改起原艺带来的效果。
是以我认为,这篇论文最大的启示是:这些小细节组合在沿途,比那些看起来很中枢的聚积组件影响更大
Ravid:对我来说,嗅觉咱们是在无数尝试各式东西,有些起效了,模子就变好了。然后回罕见来,咱们才运行真实贯通哪些组件是枢纽的。
你以为咱们是需要先有冲破,再回头贯通细节?如故说咱们只需要反复试错,不需要明确的标的?
刘壮:Transformer对通盘社区来说皆备是一个福音,把Transformer引入算计机视觉这件事,道理要紧。
是那几年里皆备是最重要的冲破之一。
但视觉Transformer还有另一个克己,即是它达成了文本和图像暗示的结伴。
Transformer的使用对自后的发展相当枢纽,比如LLaVA,这类多模态框架——用视觉编码器把图像编码成token,然后和文本token沿途输入到下流的大言语模子里。
这是现在好多多模态模子的基本框架。
回到咱们的斟酌,这种对细节的真切分析,我以为更像是一堂课。它改变了我我方的领会,也改变了好多东谈主的领会,这让我更引以为傲。
自然东谈主们如故可以连接用ConvNet,它也有我方的上风,尤其是在纯视觉任务里:部署便捷,比拟容易贯通,也因为操作是局部的,是以对更高分辨率和长序列有更好的支捏。
两种架构仅仅在不同处所各有长处。
Ravid:好,架构不那么重要——你还有一篇更近的论文,解释了归一化层也不那么重要,对吗?
基本上可以用双曲正切激活函数来取代归一化层,只需要一些退换,但效果一样好。
那你以为真实重要的中枢组件是什么?何况为什么好的AI模子仅仅在最近五年才出现,而不是十年前?

刘壮:这是个好问题。
启程点,Transformer约莫是十年前刻薄来的,九年前吧。
是以在那之后很长一段时刻里,咱们基本如故沿用类似的基本框架,只须一些小转变,比如激活层、人人搀杂(不是每次都用)、局部重观点、滑动窗口重观点等,但中枢框架和九年前论文刚出来时基本一样。
是以我的谜底是:数据,以及磨真金不怕火时使用的算计限度
这就像GPT-1到GPT-3的经典故事——基本上是归拢个模子,用更多算计量、更多数据、更各样化的数据、更大限度的互联网数据来磨真金不怕火,就得到了咱们现在看到的这些苍劲手艺。
是以我会把这归因于数据,其次是算力
我认为数据是主要成分,因为现在大多数模子磨真金不怕火的epoch数都不突出一个。
Allen:我小心到你的斟酌有一个结合经久的论点,即是这个规模时时把架构和磨真金不怕火决议同等看待。
如若你要为今天的架构论文设定例则,在有东谈主宣称某种架构选拔有价值之前,你会要求哪些律例条款?
刘壮:好,在生机全国里,咱们有无穷算计资源,对吧?
启程点,我会要求在一定例模上考证效果,不一定是前沿模子,但至少要在70亿、300亿参数这个量级。
限度对工业界来说很重要,只须在这个限度上,人人才的确会服气你的转变灵验。自然,这并不老是可行的。
其次,如若你要在较小限度上斟酌架构变化,我会要求启程点作念超参数搜索
你不成只在一组超参数下解释新架构比旧架构好,尤其是当这组超参数是专门为这个新模子调过的。
每个模子都应该在各自最优的超参数下进行比拟,最重要的超参数是学习率、衰减、优化器类型。
让我很烦的一件事是,有东谈主以致不去调基线模子的学习率,只调我方步伐的,然后就宣称灵验——这是导致好多”终局无法泛化”的最常见的问题所在。
第三,我会要求这个想法或步伐在不啻一个数据集上得到考证,最好是在一个合理限度的数据集上。
ImageNet今天仍然适用,但生机情况下,还应该在一些小限度的大言语模子上考证,比如在FineWeb上磨真金不怕火。
我相当唱和在各样的数据集上考证想法,至少要在规模内常用的数据集上。这即是我会提的几个尺度。
Ravid:如若一个想法是真实好的,它是否应该在不同规模、不同数据集、不同场景下都灵验?
如故说有些相当好的想法只适用于相当特定的场景?
刘壮:我认为两种都雷同有价值。
在第二种情况下,我但愿斟酌者能了了地证据,这个步伐在什么特定场景下更好,仍然应该在不啻一个数据集上考证。
如若你宣称你的模子在长凹凸文音频上效果更好,你仍然可以在这个方进取用多个数据集测试。
同期要解释了了,为什么这个步伐在这个特定规模好,为什么在其他规模不好,然后从这里启程,去管理那些缺欠。
这即是斟酌的价值所在——你不需要第一步就全面得胜,那诚然很好,但不是必须的。
数据集没你想的那么“各样”

Ravid:好,那咱们来聊聊数据。你说数据是最重要的。具体是数据的哪些方面?咱们先从你那篇对于“数据集偏差的几十年之争”的论文提及。你们的斟酌动机是什么?
刘壮:这篇论文主要聚焦在视觉规模。
多年来,东谈主们一直在从越来越各样化的来源构建越来越大的数据集——从启程点的MNIST,到CIFAR,再到ImageNet,再到互联网限度的DataComp、Google的ConceptualCaptions等。
这些数据集看起来越来越各样,限度从几万张到十亿级别。人人很自然地会认为:咱们照旧网罗了互联网上能拿到的悉数东西,数据集应该满盈了吧?
但在咱们的初步实验里,咱们发现这些数据集相互之间其实互异极大。
咱们是若何谋划的呢?咱们遐想了一个相当“蠢”的实验——从深度学习磨真金不怕火的角度来看完全莫得实践道理。
咱们作念的是:给定三个很大的数据集,磨真金不怕火一个神经聚积来判断一张图片来自哪个数据集
这不是什么实践问题,仅仅想猜度图片的来源,是个多分类问题。
终局发现,在这三个看似相当各样化的数据集上,模子仍然能以突出80%的准确率回答这个问题。
而立时猜度的准确率是33%,模子的准确率远远突出这个基线。
这意味着,在模子看来,这些数据集仍然相当不同,有相当表现的踪迹让模子判断图片来自何处。
自然,咱们是在留出的考证集上作念测试,不是在磨真金不怕火集上猜。
这促使咱们反想:咱们的确得胜构建了一个大限度、全面诡秘的数据集了吗?什么样的数据才是终极野心?
这个“无偏的全球分散数据集”自己就很难界说,不同的东谈主可能有不同的尺度。
大言语模子得胜的一个重要原因,是它不是规模专用的模子,它能作念悉数事。要作念到这小数,一个普遍的假定是模子在磨真金不怕火时需要见过悉数东西。
但从这个初步实验来看,咱们昭着还莫得达到阿谁进程。
Ravid:那你以为谜底是什么?好的数据需要具备哪些属性——各样性、省略情趣、幸免冗余?
刘壮:是的,内容各样性、作风各样性……深度学习的一个大教授是:
想让它擅长悉数事,就要在悉数事上磨真金不怕火它。
但在现在的条款下,咱们仍然面对衡量问题——算力有限,模子容量有限。
模子学到的不同手艺之间可能会相互竞争,比如如若你想让模子在编程上更好,可能就需要糟跶小数它在热诚筹商方面的手艺,这仅仅举个例子。
如何配比磨真金不怕火数据,让每个咱们但愿模子擅长的规模都得到满盈的暗示?这是一个重要的遐想问题。
在咱们最近一个翰墨转图像的技俩里,咱们发现了一个出东谈主料想的简陋决议——不是最优的,但满盈简陋——即是把你存眷的悉数规模大致等权重地搀杂
你不会但愿“如何剃头”和“如何编程”得到同等权重,因为它们对大多数东谈主的重要进程离别很大,你自然但愿模子在编程上见过更多数据。
但如若你把“剃头”彭胀为“日常生活手段”这个层面,把它和另一个同等重要进程的规模放在沿途,然后从每个规模网罗高质料数据并等权重搀杂,这种作念法在好多其他技俩里效果都可以。
Ravid:你以为这即是改日的标的吗?即是把各式来源简陋地搀杂在沿途?
刘壮:对于通用模子来说,是的。
如若你仅仅想让模子在悉数事情上都还可以,而不是在某个特定贫窭任务上罕见拔尖,那我认为数据诡秘是王谈
IlyaSutskever有句名言,冒昧是只须你有一个大模子,网罗了满盈多的数据,模子就一定能训好
我认为这在当代深度学习里仍然适用。
迎面对用户时,想让模子在某个任务上施展好,就在磨真金不怕火集里放满盈多这方面的数据,这是最合理的管理决议。
视觉是桥梁,但言语先点火了这把火
AllenImageBind把六种模态对皆到归拢个镶嵌空间里。
你以为这是在证据视觉模态自己的特别地位,如故仅仅证据了视觉数据在大限度数据中巧合有这样的变装?

刘壮:我以为这篇论文一个很重要的信息是:不同模态如实可以被镶嵌在沿途,这是现在多模态基础模子运作样子的基础
常见的作念法是用编码器把每个模态对皆到言语模子的token暗示。
ImageBind更专注于学习编码器自己,而不是把它们勾通到大言语模子上。
另一个洞见是:视觉是勾通悉数模态的自然桥梁,因为视觉数据就像是咱们东谈主类的默许输入。
它时时和好多其他模态同期出现,比如音频——看YouTube视频时,音频和视觉数据自然地会通在沿途,你可以用这个信号来对皆两者。
还有畅通数据,也时时和图像或视觉数据同期出现。这揭示了视觉在咱们日常感知中的根人性地位。
Ravid:但为什么最终手艺上的大跃升是通过言语模子达成的?
咱们有视觉好一段时刻了,但莫得看到AI在悉数规模、悉数公司里大限度普及。直到言语模子变强,东谈主们才俄顷运行用AI。
你以为这仅仅巧合,如故言语自己有什么根人性的上风?
刘壮:是的,这是个被豪放筹商的话题。
我的贯通是:视觉实质上是模糊量相当高的数据——它流入咱们感知系统的带宽远高于言语,而咱们还莫得满盈的算力来真实处理这些数据
想想看,就一帧图像,快乐彩app下载存储它所需的空间就开阔于用言语描摹这张图像——描摹可能只需要几个字节,图像却需要几千字节,收支上千倍。
是以一张图片的信息量如实突出一千个词。
另外,咱们也莫得好的机制让模子在图像上作念清雅定位——在现时的多模态言语模子里,悉数信息都照旧编码在视觉token里了,模子莫得主张回头去重新聚焦图像的某个区域。
如若视觉编码器质料不好,自转头模子对此毫无主张。
而言语处于一个低维得多的空间,每个词都有明确的含义——这有点像东谈主类从自然界里作念无监督学习。
咱们在进化经过中筛选出了这些重要认识,把它们凝缩成词,每个词只需要几个字节的存储空间,而用图像来暗示”杯子”这个认识,可能需要千千万万张图片。
处理这样无数信息所需的算力自然要高得多,我以为咱们目下还莫得到阿谁进程。
Allen:好,然后是那篇我很可爱标题的论文——《EyesWideShut》,斯坦利·库布里克的临了一部电影。
你在论文里刻薄,好多多模态大言语模子的失败,都可以记念到CLIP这样的视觉编码器以及CLIP的盲点。
能抽象一下这篇论文吗?在你看来,这个瓶颈究竟有些许是视觉问题,又有些许是言语模子或对皆问题?

刘壮:我认为这在很猛进程上是视觉编码器的问题
正如我之前说的,这些模子只会学磨真金不怕火时教它们学的东西。如若磨真金不怕火时莫得让模子面对你但愿它擅长的任务类型,测试时它就不会好。
具体来说,CLIP磨真金不怕火的野心是让图像暗示和它的翰墨描摹对皆。而图像描摹自然地更关注图像的内容——里面有什么物体,它们在作念什么——而不太会明确证据这些物体的位置
如若图中有一个东谈主和一条狗,描摹好像只会说“东谈主和狗玩耍”,而不会说东谈主在左边如故右边——这是咱们东谈主类描摹图像时很自然的样子。
对东谈主来说这没问题,咱们不太在乎谁在左边。但如若你但愿模子能够回答这类位置关联的问题,就需要在磨真金不怕火里用到这些。而这正是CLIP磨真金不怕火所忽略的。
终局咱们得到一个被用作多模态言语模子视觉编码器的CLIP模子,它根蒂没被磨真金不怕火行止理这些任务。
这再次印证了我的不雅点:想让模子擅长什么,就要在那件事上磨真金不怕火它
Allen:在《EyesWideShut》那篇论文里,你建议把视觉特征和自监督特征搀杂来改善视觉定位。
如若同期优化言语对皆和细粒度视觉辨别,你认为多模态言语模子最生机的视觉编码器应该是什么样的?
刘壮:我现在心里想的管理决议即是两者都作念。这两种是现在视觉预磨真金不怕火的两大主流范式。
我还想加一个——现在好多东谈主在筹商全国模子——我会在视觉部分加入时刻维度,这也会相当有匡助。
大言语模子有全国模子,但只在言语空间里
Ravid:咱们来聊聊全国模子。你对全国模子的界说是什么?
刘壮:对我来说,全国模子即是预计全国如何运作,笔据你现时的景象来预计全国接下来会发生什么。
Ravid:这具体是什么瞻仰?
比如几周前StephaneMallat来这里宣称大言语模子有全国模子,而之前YannLeCun来这里说咱们需要显式地构建全国模子,目下的大言语模子并莫得。
你若何看?你以为咱们能界说出一个尺度,来判断哪些模子有全国模子、哪些莫得?
刘壮:是的,我认为大言语模子在言语空间里是有全国模子的,这毫无疑问。
言语是咱们所摄取的悉数感知信号的更高级次的抽象,大言语模子在这个层面上有着罕见好的全国模子。
我时时和ChatGPT筹商历史。几天前我让它遐想一个假定场景:中国历史上某个事件里,我让ChatGPT遐想如若阿谁失败的势力赢得了斗争,历史会若何变?
它给出的回答相当合理——把悉数小事件串联起来,一切都讲得通,仅仅一些小概率的决策偏移,然后一切随之改变,像真实历史一样,完全有可能即是真实历史。
在这个道理上,我以为莫得哪个演义家或历史学家能超越它在这串事件中的逻辑推理水平。
是以它们如实有一个很好的全国模子,只不外是在相当高的抽象档次上
当咱们说“咱们现在莫得全国模子”,说的其实是视觉空间的全国模子——咱们没法在像素空间里完整地还原或模拟全国,这亦然的确。
我认为模子有莫得全国模子,取决于你想对全国的哪个档次建模。
如若你把全国的高级次事件视为一个自包含的全国,那咱们通过言语模子如实有。
但如若你把每个像素、每个原始信号、每个物理信号,包括全国上每种物资的物理属性,都纳入考量,那咱们如实还莫得阿谁档次的清雅化模子。
根蒂原因如故视觉数据的模糊量太高,咱们还莫得满盈的算力来齐全地对它建模。
Ravid:那你以为咱们的确需要全国模子来管理99%的任务吗?
刘壮:对于数字化责任,比如白领责任,我认为不需要视觉全国模子。
好多事情都在数字空间里运作,我最多需要模子能读取我的电脑屏幕,而屏幕内容可以被数字化或压缩,泛泛最多是一组图像,不是及时视频流,这相对容易。
我目下用ClaudeCode的瓶颈之一即是需要截屏,这个问题应该很快可以管理,因为这些模子可能很快就能以安全的样子打听咱们的屏幕。
但对于膂力处事,比如建筑、驾驶、膂力行径,我认为如实需要视觉模子,因为这类责任中的响应是曲常细粒度的。
还有剃头——你想剪哪部分头发、剪些许,这是没法靠言语模子来完成的。
还有一些物感性的责任,比如外科手术。我认为,真实需要视觉全国模子手艺作念好的责任,不会突出一半
顾忌才是真实的瓶颈,智能体仅仅权宜之策
Ravid:你若何看强化学习?
现在悉数实验室都在建我方的环境,想在编程或某些特定任务上作念得更好,就搭一个专用环境,让模子在这个环境里磨真金不怕火,给它响应和奖励。
你以为这是改日的标的吗?
刘壮:是的,实践上我省略情每个实验室都这样作念强化学习或监督微调是否的确可行。
我但愿改日能有一套像预磨真金不怕火一样老练的步伐来作念捏续磨真金不怕火。可以是强化学习,也可以是情境工程、辅导工程、智能体配合,这些都如故怒放的。
也许还需要退换架构,让模子有更大的顾忌、更长的凹凸文。
捏续学习这件事,把通用模子适配到特定规模,我认为相当重要。
因为每个东谈主在一世中会遭逢不同的情境。你但愿模子成为你的好助手,赋能你的生活和责任,你需要它记取无数凹凸文。
在这方面,东谈主脑仍然远超模子——极大的顾忌容量,快速学习,只需见一次就能记取一个事实,何况不会健忘。
你今天用ClaudeCode时,最让我系念的即是它是否还谨记我之前作念过的事,我服气好多东谈主都有这个感受。
在咱们各自的业绩生活里,有太多东西但愿模子记取,毋庸每次都重新解释。
不是什么特定任务,而是悉数一切——咱们与他东谈主的互动样子、以前的建设和失败等等。
我以为这个谜底可能不仅仅强化学习,更像是系统工程——若何组织一切,让模子能松驰打听所需信息。
说到底如故数据问题:若何组织数据,若何提供满盈的数据,若何整合来自不同来源、不同输入的数据。也许以后咱们会戴智能眼镜,给这些模子提供视觉输入。
Ravid:但你以为基本的组件照旧到位了,如故会保捏不变?
咱们仅仅需要搭好脚手架——比如若何让智能体辞全国里行动、网罗数据、组织顾忌这些事情?如故说咱们需要从根蒂上改变什么?
刘壮:是的,这是个很好的问题。
有一个令东谈主缺憾的现实是:不是每个东谈主都能在这些超大模子的基础层面上作念斟酌,只须背负得起磨真金不怕火本钱的东谈主手艺作念实验。
是以现在咱们看到无数的智能体责任——因为这险些是好多东谈主能对系统作念出改良的唯独样子。
智能体很好,但我小心到,我构建的每一套智能体系统,每一个脚手架——比如我试图搭一个能让ClaudeCode万古刻运行的框架——
泛泛过几周或几个月,我会找到一个更简陋的管理决议,比如用辅导或一些内置号令和手段来达成雷同的效果,而不需要Python脚手架这类东西。
是以我认为最大的教授是:保捏系统简陋,让模子我方作念好多决定
缺憾的是,不是每个东谈主都能为底层模子手艺的升迁作念孝敬。
咱们能作念的是情境工程和智能体。但在基础手艺方面,我认为咱们仍然可以追逐。
咱们现在存眷的每一个任务,在一定的性能水平上,都可以用更少的智能体、更少的脚手架来完成,而更多地依赖模子自己的手艺。
我认为咱们仍然处在这条弧线上。
Ravid:但咱们为什么要介怀呢?在算力和数据越来越多的全国里,为什么不就成功搭智能体管理悉数问题?
刘壮智能体如故会犯错——代码智能体亦然。
我遭逢的好多伪善都是因为它记不住某些东西,这很昭着,应该是不问可知的。
是以我认为在顾忌方面——顾忌和凹凸文——这是目下最重要的问题,尤其是顾忌。它们是一枚硬币的两面。
即使你有无穷的凹凸文,如若它健忘了或者记错了事实,它的顾忌力仍然不好。
ClaudeCode前几天秘书支捏100万token的凹凸文窗口,人人都很振奋,包括我,这很好。
但咱们怎么手艺领有无穷的顾忌?至少是捏续学习问题——怎么手艺不健忘?
我以为这比若何构建配合智能体更重要,如若咱们在这方面赢得冲破,会更有价值。
咱们需要好多智能体,恰正是因为一个智能体记不住悉数事情,需要拆分任务。
如若一个智能体能记取悉数事情,作念完这个任务还不健忘上一个任务,那悉数责任就可以交给这一个智能体完成。
算作个东谈主助手,有一个能记取悉数事情的助手,总比和洽多个智能体更便捷。
Allen:你还有一篇我很感兴致的论文——《大言语模子中的特异性》,发现模子独到的特征在改写、翻译、摘要之后仍然保留。
你以为这些“指纹”到底在度量什么?是预磨真金不怕火数据、磨真金不怕火后的作风、解码行径,如故更底层的结构性成分?

刘壮:这篇论文作念的是雷同的分类任务——给定一段文本,让一个孤苦的神经聚积判断它是由哪个言语模子生成的。
咱们发现准确率可以相当高,在五个候选模子的情况下可以达到99%。
其时对咱们来说也挺出乎料想的。
但现在我认为人人越来越给与一件事:言语模子生成的文本里如实存在踪迹,即使不是AI斟酌者的普通东谈主也能判断出好像是哪个模子写的。
现在这不再那么令东谈主讶异了,因为每家公司都有我方的政策来最大化用户参与度,导致模子输出了不同的作风。
到底是什么形成了这些互异?我认为每家提供商对作风的选拔相当枢纽——系统辅导,咱们看不到他们的系统辅导,他们有莫得让模子输出详备或马虎,有莫得用列表?
后磨真金不怕火政策也有很大影响,不同公司的后磨真金不怕火样子不同,他们招募标注员的样子、评分尺度都会有系统性互异,这些都会饱读舞不同的行径形式。
预磨真金不怕火也有影响,每家公司的预磨真金不怕火数据来源不同,有些侧重编程和数学推理,有些优化通用常识诡秘。
令东谈主缺憾的是,咱们不知谈这些互异各自孝敬些许。
总体来说,我认为后磨真金不怕火和系统辅导的遐想是形成互异的主要原因,占大部分比重。
Ravid:你若何看预磨真金不怕火这件事?预磨真金不怕火、中磨真金不怕火、后磨真金不怕火这种阔别会连接存在吗?
刘壮:我认为预磨真金不怕火和中磨真金不怕火相互更相似,都和后磨真金不怕火有所不同。
后磨真金不怕火的奖励信号是不同的,因为它波及到东谈主类判断和东谈主类偏好。
预磨真金不怕火和中磨真金不怕火实质上都是自转头,仅仅数据作风和凹凸文长度不同。
中磨真金不怕火是个比拟新的认识,几年前咱们只须预磨真金不怕火和后磨真金不怕火,现在多了一个中磨真金不怕火。
中磨真金不怕火有时是一种临时景象,因为中磨真金不怕火的中枢是彭胀凹凸文长度、引入更高质料的数据

我莫得这些公司的里面信息,但我以为这可能是一种和解——咱们莫得满盈的算力经久在超长凹凸文上磨真金不怕火、经久在最高质料数据上磨真金不怕火。
是以预磨真金不怕火和中磨真金不怕火可以统称为“预磨真金不怕火”,引号里的那种。
后磨真金不怕火不同,因为它波及东谈主类对模子行径的主动指点,这种区别不会隐匿。
但我但愿改日还有另一个阶段——针对每个用户定制的捏续磨真金不怕火,定制偏好、顾忌需求、使用作风,那会相当好。
Ravid:你若何看捏续学习?是像自监督学习那样从不同视角的互异里学习?
如故针对特定任务,有了新数据再管理特定问题?
刘壮:我认为捏续学习不太是对于增强手艺的。我更景象把它看作更好的顾忌。
这些模子已有的手艺照旧很好了,它们能解出大多数东谈主解不了的数学题。
咱们需要的是让模子记取每个东谈主的个性风气——我会如何回复某些事件?我有哪些基本原则?
即使我把我方生活里悉数的履历和偏好都写在一个Markdown文献里,它如故可能遗漏。
比如我现在有一个全局的ClaudeMD文献,告诉模子遭逢某些情况时要小心什么,但它们时时如故会忽略。
我莫得好的主张让这些内容真实“粘”在模子上。
是以我一直认为,捏续预磨真金不怕火更多是对于领有领会的顾忌、不在小事上犯错,而不是发展更多手艺
是找到在安妥场景下使用正确手段的手艺,而不是发展更苍劲的手段。
Ravid:你若何看这件事?
我好像在LinkedIn或Twitter上看到有东谈主说,有了新的编程智能体,他不再需要学生了,成功告诉智能体想作念什么,让它跑实验、出终局、写证明就行了。
你以为咱们会看到更多学生如故更少学生?
刘壮:从教悔角度来说,我认为咱们需要更多深度进入其中的学生,需要能够使用AI并进一步鞭策AI发展的学生。这小数不应该有什么争议。
从实践技俩的角度,我认为谜底是一样的。
只须有合理的资源和时刻,我现在可以用ClaudeCode我方作念一个小技俩。但这不是全自动的。
我也曾让它在一两天内孤苦完成一个技俩,从构料到实验到写论文,但效果不好——
刻薄的问题很磨蹭,对我来说没什么瞻仰;作念的实验不够全面,仅仅凑合能扶直论断;我需要反复辅导手艺把它引到正确的标的。
它健忘事情的频率也超出我的预期。我让它一直用某个GPU分区,它可能战胜几个小时,任务完成后就忘了。
我但愿它永继续歇,笔据现时实验终局继续探索、遐想下一个实验测试新假定,但它即是不听,有时候会堕入局部最优。
是以我认为它们擅长低档次的任务,在更高级次的斟酌贯通和导航上还不够好

学生也可以像我一样,让ClaudeCode帮我方提高责任效力。
何况如若他们有正确的心态,不把悉数事情都奉求给AI,他们仍然会在这个经过中成长,成为好的斟酌者。
我认为咱们需要更多这样的学生,不是更少。
Ravid:你传闻过吗,AndrejKarpathy发布了AutoResearch,即是给一个代码智能体去优化NanoGPT,让它连夜跑多个实验,终局考证蚀本如实不才降。
刘壮:对,对。
Ravid:智能体刻薄的一个建议是改变立时种子,然后终局就变好了好多。
我我方也试过类似的事,即是对这个技俩作念了个很简陋的贝叶斯优化,超参数搜索。
终局发现用更少的迭代次数、更短的时刻就能得到更好的终局。
我以为最终咱们需要搞了了,哪些用法真实灵验,哪些还没到位,哪些仅仅因为看起来好意思丽、人人都用,是以咱们在糜费时刻去辅导它。
刘壮:嗯。
Ravid:是以,我应承你的判断,自主斟酌目下还没到阿谁阶段。
改日会不会到,我不知谈,也许会。但至少对某些场景,对某些用途,用来培植居品照旧罕见可以、接近可用了。
刘壮:嗯,嗯。
Ravid:但在斟酌方面,还没到。
刘壮:如实快乐彩app官方最新版下载,这亦然我的亲自体验。
江南体育(JNsports)官网app下载 备案号:
备案号: